Building Kaizen: How We Cut Token Costs by 60% and more Without Changing Data Formats
When one of our enterprise customers asked us to process an unusually large and complex document, we faced a performance and cost challenge. The document extraction pipeline involved multiple agents parsing, validating, and enriching the content before it could be pushed into production. The problem was not the logic it was the size. Our JSON-based prompts were consuming a massive number of tokens, inflating API costs and latency.Identifying the Problem
Our stack relied heavily on structured JSON for document extraction because switching to YAML or other compact formats would break compatibility with our downstream systems. The token usage was high due to whitespace, repeated keys, and verbose nested structures. While this might seem trivial, the costs compound fast when you are parsing thousands of documents in an automated workflow.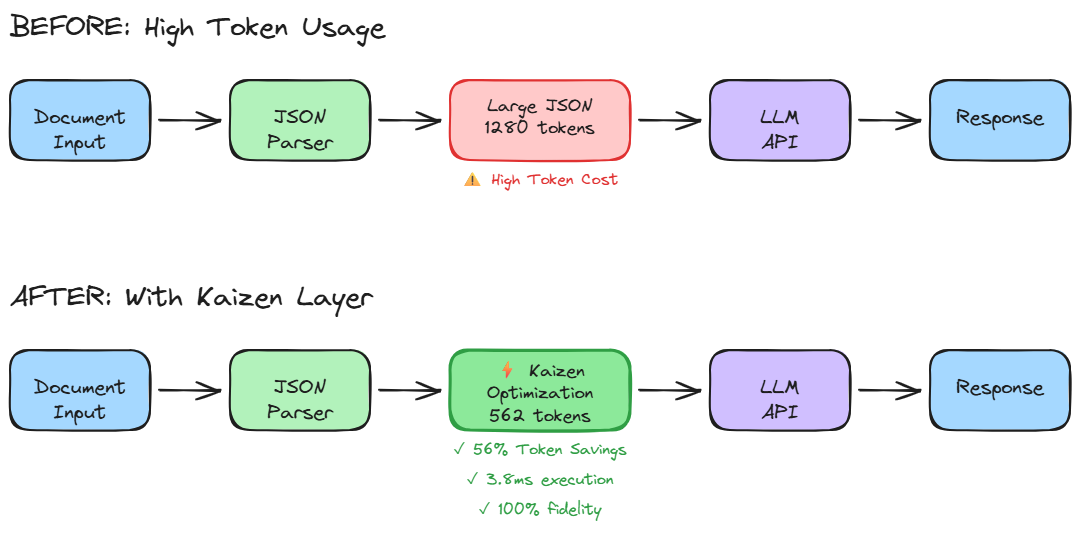
The Breakthrough: Token Optimization Without Structural Change
We knew that prompt optimization could yield real savings if done safely. The challenge was preserving 100% correctness while trimming redundant data. So, we built a lightweight internal library called Kaizen, a token optimization layer designed to make JSON leaner and smarter. Kaizen’s first iteration focused on removing unnecessary whitespace, redundant keys, and repeated syntax elements. But as we scaled, we encountered nested JSON objects, CSV-like payloads, and SQL-style results. The complexity required a more intelligent compression logic.Engineering Kaizen
To meet enterprise-grade performance standards, our design goals were: Speed: Perform optimizations within 4 milliseconds per request.Safety: Guarantee 100% fidelity of original data after round-trip (JSON → optimized → JSON).
Compatibility: Work seamlessly with JSON, CSV, and SQL result sets.
Observability: Provide measurable savings in token usage and dollar cost per run. Kaizen uses a deterministic encoder-decoder pipeline. Every payload passes through a compression layer that tokenizes and reconstitutes structure-aware segments. It ensures that the round-trip transformation is safe, preserving booleans, nulls, and number types without conversion loss.
Results
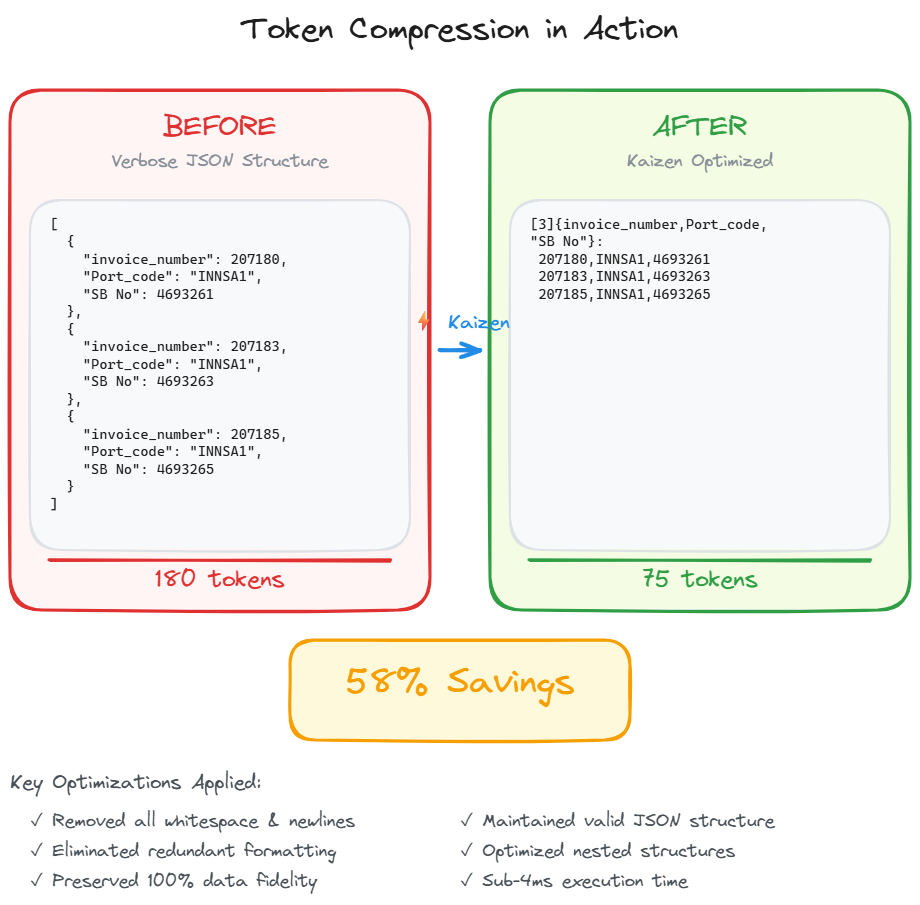
- 50–60% reduction in token usage, depending on document complexity.
- Instant cost savings, as the same prompts consumed half the tokens per model call.
- Negligible latency impact, maintaining sub-4ms execution.
- 100% field accuracy, validated against our extraction engine.

From Internal Tool to Developer Library
What began as a one-off optimization quickly evolved into a standalone client library. The Kaizen client now provides APIs for real-time token analysis, prompt optimization, and safe reconstruction of structured data. It supports multi-format data inputs and can be integrated into both frontend and backend pipelines.The Developer Experience is simple
Why It Matters
Kaizen is not just a library it is an approach to efficiency. In a world where prompt tokens are currency, optimizing every byte without sacrificing fidelity can yield massive ROI at scale. By staying within the JSON ecosystem and pushing the boundaries of micro-optimizations, Kaizen proves that developer-first efficiency can coexist with accuracy and speed. If you are building agentic document pipelines or handling high-frequency LLM requests, you can explore integrating Kaizen.Every token saved is a dollar earned and every millisecond matters.